Every team that discusses microservices migration hears the warnings: it is complex, risky, and often unnecessary. But for our client — a growing SaaS platform with 50,000 active users — the monolith had become a genuine bottleneck. Here is how we executed the migration.
Why the Monolith Had to Go
The client's platform was built as a PHP monolith five years earlier. It served them well during the early growth phase, but several pain points had become critical:
- Deployment risk — Every deployment touched the entire application. A change to the billing module could break user authentication
- Scaling limitations — The search feature needed 10x more compute than the rest of the app, but everything scaled together
- Development velocity — With 15 developers working in the same codebase, merge conflicts and coordination overhead were constant
- Technology lock-in — The entire application was bound to a single technology stack, preventing adoption of better tools for specific tasks
Our Migration Strategy
We adopted the Strangler Fig pattern — gradually replacing parts of the monolith with microservices while keeping the system fully operational throughout.
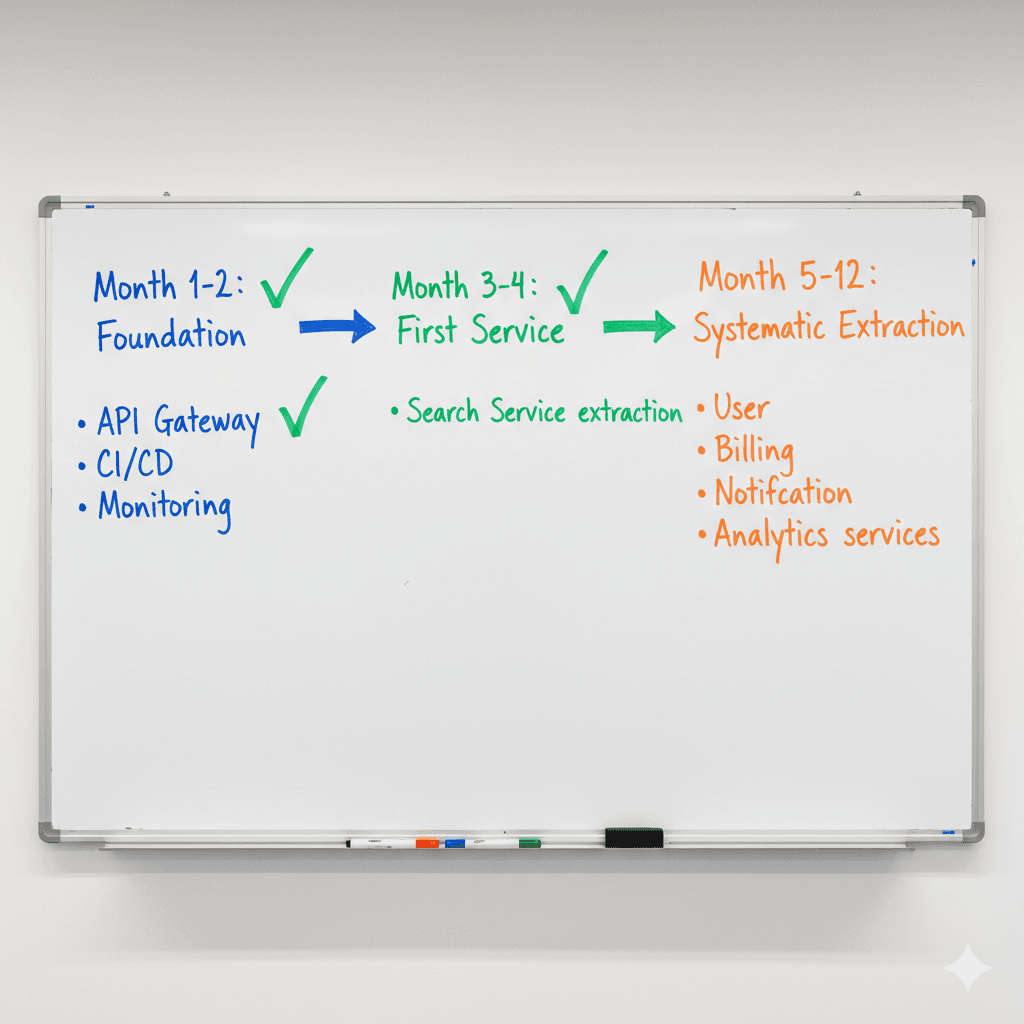
Phase 1: Establish the Foundation (Month 1-2)
Before extracting any services, we built the infrastructure:
- API gateway for routing requests
- Service discovery and configuration management
- Centralized logging and monitoring
- CI/CD pipelines for independent service deployment
Phase 2: Extract the First Service (Month 3-4)
We started with the search service — it had clear boundaries, high resource demands, and minimal data dependencies. The monolith's search functionality was replaced by a new Elasticsearch-powered microservice behind the API gateway.
Phase 3: Systematic Extraction (Month 5-12)
Over the following months, we extracted services based on business domain boundaries:
- User Service — Authentication, profiles, permissions
- Billing Service — Subscriptions, invoicing, payments
- Notification Service — Email, SMS, push notifications
- Analytics Service — Usage tracking and reporting
Phase 4: Decompose the Database (Ongoing)
The hardest part was splitting the shared database. We used an event-driven approach where services publish events on state changes and other services maintain their own data stores.
What Worked
- Starting with infrastructure — Having monitoring and deployment automation in place before the first extraction was critical
- Business-driven boundaries — Services aligned with business capabilities, not technical layers
- Incremental approach — The system was never down. Users experienced zero disruption
- Dedicated migration team — A cross-functional team focused solely on the migration
What We Would Do Differently
- Earlier investment in event-driven architecture — We underestimated the complexity of data synchronization
- More comprehensive contract testing — Some integration issues could have been caught earlier
- Better documentation of the monolith — Understanding existing behavior was harder than expected
The Results
After 12 months:
- Deployment frequency increased from weekly to daily
- Mean time to recovery dropped from hours to minutes
- Search performance improved by 5x with dedicated infrastructure
- Developer productivity increased as teams owned independent services
The migration was one of the most challenging projects we have undertaken, but the results validated the investment. The client now has a platform that can scale with their growth for years to come.